
¿Por qué el Machine Learning es tan importante para las industrias actuales?
Por Antonio Richaud, Publicado el 8 de Mayo de 2024
En un mundo empresarial cada vez más competitivo y dinámico, la capacidad de tomar decisiones informadas y optimizar procesos es más importante que nunca. Aquí es donde entra en juego el Machine Learning (ML), una rama de la inteligencia artificial que ha demostrado ser un recurso invaluable para las industrias modernas. Desde predecir comportamientos del cliente hasta mejorar la eficiencia operativa, el Machine Learning está transformando la manera en que las empresas abordan sus desafíos más complejos.
Pero, ¿qué es exactamente el Machine Learning y por qué es tan relevante para las industrias de hoy en día? En términos simples, el ML se centra en desarrollar sistemas que pueden aprender de los datos y mejorar su desempeño en tareas específicas sin ser programados explícitamente para cada una. Esto lo convierte en una herramienta poderosa para sectores como las finanzas, la manufactura, el retail, y muchos otros, donde la capacidad de analizar grandes volúmenes de datos y hacer predicciones precisas puede marcar la diferencia entre el éxito y el fracaso.
En este artículo, exploraremos cómo el Machine Learning está revolucionando diversas industrias, desde la predicción de incumplimiento de crédito en el sector financiero hasta la optimización de la cadena de suministro en la manufactura. Veremos ejemplos prácticos y casos de uso específicos que demuestran cómo el ML está ayudando a las empresas a tomar decisiones más inteligentes, reducir costos y mejorar la satisfacción del cliente. Además, discutiremos por qué el Machine Learning es una parte integral de la transformación digital que muchas industrias están experimentando hoy en día, y cómo puedes comenzar a aplicarlo en tu propia empresa.
Machine Learning vs. Inteligencia Artificial
Aunque a menudo se utilizan como sinónimos, Machine Learning (ML) e Inteligencia Artificial (IA) no son lo mismo. En términos simples, la IA es un campo más amplio que busca crear sistemas capaces de realizar tareas que normalmente requieren inteligencia humana, como la toma de decisiones, el reconocimiento de voz o la resolución de problemas complejos. Dentro de este vasto campo, el Machine Learning se especializa en enseñar a las máquinas a aprender de los datos, lo que lo convierte en una herramienta especialmente poderosa para resolver problemas empresariales.
¿Qué es la Inteligencia Artificial?
La Inteligencia Artificial abarca una serie de tecnologías y técnicas diseñadas para simular la inteligencia humana en las máquinas. Esto incluye desde simples reglas if-then hasta sistemas más complejos como los que controlan vehículos autónomos o permiten a los asistentes virtuales como Siri o Alexa entender y responder a comandos de voz. En el contexto empresarial, la IA puede automatizar procesos, mejorar la eficiencia y proporcionar nuevas formas de interactuar con los clientes.
¿Qué es el Machine Learning?
El Machine Learning, por otro lado, se centra en la capacidad de las máquinas para aprender de los datos y mejorar con el tiempo sin intervención humana constante. Esto es especialmente útil en entornos empresariales donde los datos son abundantes y las decisiones deben adaptarse a cambios rápidos. Por ejemplo, en el sector financiero, los modelos de ML se utilizan para predecir el riesgo de crédito, detectar fraudes, y automatizar la toma de decisiones basadas en grandes volúmenes de datos históricos y en tiempo real.
Ejemplo técnico: Predicción del incumplimiento de crédito en el sector financiero
Para ilustrar cómo el Machine Learning se aplica en un contexto empresarial, consideremos el caso de la predicción del incumplimiento de crédito. En el sector financiero, las instituciones necesitan evaluar el riesgo de que un cliente incumpla el pago de un préstamo. Un modelo de ML puede analizar datos históricos de miles de clientes para identificar patrones y predecir con alta precisión si un nuevo solicitante tiene un alto riesgo de incumplir.
# Importar las bibliotecas necesarias
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn.datasets import fetch_openml
# Cargar el conjunto de datos 'credit-g' de OpenML (un conjunto de datos de crédito)
data = fetch_openml('credit-g', version=1, as_frame=True)
df = data.frame
# Filtrar solo las columnas numéricas
numerical_df = df.select_dtypes(include=[np.number])
# Visualización inicial: Correlación entre variables
plt.figure(figsize=(12,8))
sns.heatmap(df.corr(), annot=True, cmap='coolwarm')
plt.title('Mapa de calor de correlación entre variables')
plt.show()
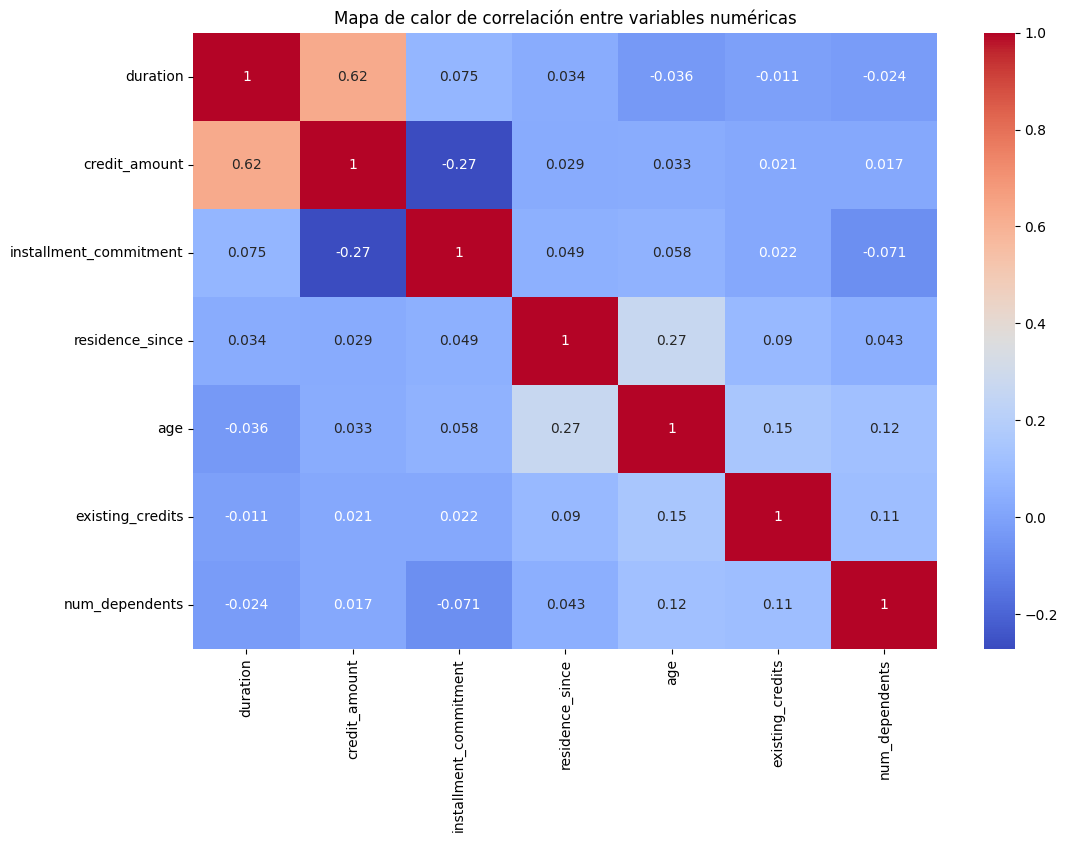
En el análisis de datos empresariales, es fundamental entender cómo las diferentes variables se relacionan entre sí antes de entrenar un modelo de Machine Learning. El mapa de calor que ves a continuación muestra la correlación entre diversas variables numéricas en el conjunto de datos de crédito, un paso esencial para la preparación de datos en contextos como la predicción del incumplimiento de crédito.
La correlación es una medida que indica la relación entre dos variables, y puede variar entre -1 y 1:
- 1: Indica una correlación positiva perfecta, es decir, cuando una variable aumenta, la otra también lo hace de manera proporcional.
- -1: Indica una correlación negativa perfecta, lo que significa que cuando una variable aumenta, la otra disminuye.
- 0: Sugiere que no hay una correlación lineal significativa entre las variables.
En el mapa de calor, observamos varias correlaciones clave:
- Duración del crédito (
duration) y Monto del crédito (credit_amount): Tienen una correlación positiva relativamente alta (0.62). Esto sugiere que, en general, los créditos de mayor duración tienden a estar asociados con montos de crédito más altos. - Compromiso de la cuota (
installment_commitment) y Monto del crédito (credit_amount): Muestran una correlación negativa (-0.27), indicando que, en promedio, créditos más grandes tienden a tener compromisos de cuota relativamente más bajos. - Otras variables como Edad (
age), Créditos existentes (existing_credits), y Dependientes (num_dependents) muestran correlaciones más bajas, lo que sugiere que estas variables no tienen una relación lineal fuerte con las demás en este conjunto de datos.
Comprender estas correlaciones es crucial para desarrollar un modelo de Machine Learning robusto. Por ejemplo, la alta correlación entre la duración y el monto del crédito puede afectar las predicciones si no se maneja adecuadamente, lo que podría llevar a problemas como la multicolinealidad. Al identificar y comprender estas relaciones, podemos ajustar nuestro modelo para mejorar su precisión y su capacidad para generalizar a nuevos datos.
# Separar las características y la etiqueta objetivo
X = df.drop('class', axis=1) # Características (sin la columna de objetivo)
y = df['class'].apply(lambda x: 1 if x == 'bad' else 0) # Etiqueta (1 si el cliente incumplió, 0 si no)
# Convertir variables categóricas en variables numéricas mediante OneHotEncoding
X_encoded = pd.get_dummies(X, drop_first=True)
# Dividir el conjunto de datos en entrenamiento y prueba
X_train, X_test, y_train, y_test = train_test_split(X_encoded, y, test_size=0.3, random_state=42)
# Entrenar un modelo de Random Forest
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Importancia de características
importances = model.feature_importances_
indices = np.argsort(importances)[::-1]
plt.figure(figsize=(10,6))
plt.title("Importancia de las características")
plt.bar(range(X_train.shape[1]), importances[indices], align="center")
plt.xticks(range(X_train.shape[1]), X_train.columns[indices], rotation=90)
plt.show()

Una vez que el modelo de Machine Learning ha sido entrenado, es crucial entender qué características o variables son más influyentes en las predicciones realizadas por el modelo. La siguiente gráfica muestra la importancia relativa de cada característica utilizada por un modelo de Random Forest para predecir el incumplimiento de crédito.
En esta gráfica, podemos observar que la característica más importante es el monto del
crédito (credit_amount), lo que sugiere que el monto solicitado es un
factor determinante en la evaluación del riesgo de incumplimiento. Otro factor significativo es
el estado de cuenta corriente (checking_status_no checking), lo
cual podría indicar que la falta de una cuenta corriente o un saldo bajo son fuertes indicadores
de riesgo.
Otras características como la edad (age), la duración del
crédito (duration), y el compromiso de la cuota
(installment_commitment) también juegan un papel importante en el
modelo. Esto resalta la importancia de estos factores en la evaluación de la solvencia
crediticia por parte de las instituciones financieras.
Comprender la importancia de estas características no solo ayuda a mejorar el modelo, sino que también proporciona información valiosa para la toma de decisiones en el ámbito empresarial, permitiendo a las organizaciones enfocar sus esfuerzos en las áreas que realmente impactan la predicción del riesgo.
# Hacer predicciones
y_pred = model.predict(X_test)
# Evaluar el modelo
accuracy = accuracy_score(y_test, y_pred)
print(f'Precisión del modelo: {accuracy * 100:.2f}%')
# Matriz de confusión para ver el rendimiento
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(cm, annot=True, fmt="d", cmap="Purples")
plt.title('Matriz de confusión')
plt.xlabel('Etiqueta Predicha')
plt.ylabel('Etiqueta Real')
plt.show()
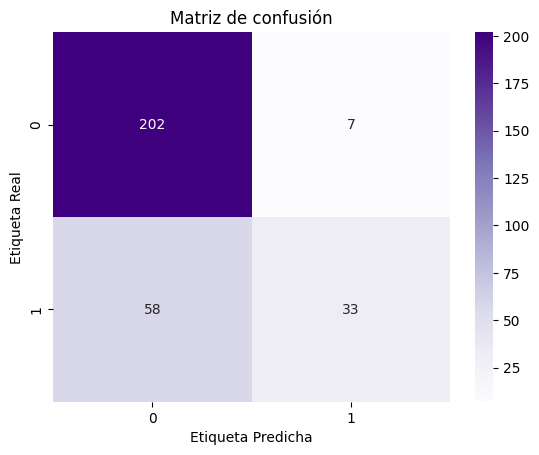
La matriz de confusión es una herramienta clave para evaluar el rendimiento de un modelo de clasificación en Machine Learning. En el contexto del riesgo crediticio, esta matriz nos permite entender cuántas veces el modelo predijo correctamente si un cliente incumpliría o no un crédito, y cuántas veces se equivocó.
En la matriz, podemos observar lo siguiente:
- Verdaderos Negativos (202): El modelo predijo correctamente 202 veces que un cliente no incumpliría el crédito.
- Falsos Positivos (7): El modelo predijo incorrectamente que 7 clientes incumplirían el crédito cuando en realidad no lo hicieron.
- Falsos Negativos (58): El modelo no identificó a 58 clientes que realmente incumplieron, prediciendo erróneamente que no lo harían.
- Verdaderos Positivos (33): El modelo predijo correctamente que 33 clientes incumplirían el crédito.
La precisión global del modelo es del 79.17%, lo que indica que, en general, el modelo fue capaz de predecir correctamente el resultado de la mayoría de los clientes. Sin embargo, es importante notar que el modelo tiene un número considerable de falsos negativos (58), lo que sugiere que algunos clientes que incumplieron no fueron identificados correctamente.
Para las instituciones financieras, es esencial ajustar y mejorar el modelo para minimizar estos errores, especialmente si el costo de no identificar a un cliente que puede incumplir es alto. Esto podría implicar ajustar el umbral de decisión del modelo o utilizar técnicas más avanzadas de Machine Learning.
Este ejemplo muestra cómo un modelo de Machine Learning puede ser entrenado para predecir el riesgo de incumplimiento de crédito en el sector financiero. Mediante la visualización de la correlación entre variables, la importancia de las características y el uso de una matriz de confusión, podemos evaluar el rendimiento del modelo y entender mejor qué factores son más influyentes en la predicción.
Diferencias clave entre ML e IA en el contexto empresarial
En el contexto empresarial, la IA se utiliza para una amplia gama de tareas, desde la automatización de procesos hasta la mejora de la experiencia del cliente. Sin embargo, el Machine Learning es particularmente útil cuando se trata de analizar grandes volúmenes de datos y hacer predicciones basadas en esos datos. Esto lo hace ideal para aplicaciones como la previsión de demanda, la detección de fraudes, y la optimización de operaciones, donde la capacidad de aprender y adaptarse a nuevos datos en tiempo real es crucial.
En resumen, mientras que la IA abarca un amplio espectro de tecnologías, el Machine Learning es un enfoque especializado que permite a las empresas extraer valor de sus datos y tomar decisiones más inteligentes. Esta capacidad de aprender y mejorar continuamente es lo que hace que el ML sea tan poderoso y relevante para las industrias actuales.
Casos de uso transformadores en la industria
El Machine Learning ha demostrado ser una herramienta poderosa en una variedad de industrias, permitiendo a las empresas transformar datos en decisiones accionables. A continuación, exploraremos algunos de los casos de uso más impactantes en sectores clave como las finanzas, el retail, la manufactura, y los recursos humanos.
1. Finanzas: Análisis predictivo y detección de fraudes
En la industria financiera, el Machine Learning está siendo utilizado para predecir el comportamiento de los clientes, detectar fraudes, y evaluar riesgos de crédito. Como hemos visto en los ejemplos anteriores, los modelos de Machine Learning pueden analizar grandes volúmenes de datos históricos para identificar patrones que ayudan a las instituciones financieras a tomar decisiones informadas. Por ejemplo, un banco puede utilizar ML para determinar la probabilidad de que un cliente incumpla el pago de un préstamo, como lo vimos en la matriz de confusión.
Además, el ML es crucial en la detección de fraudes, donde algoritmos avanzados analizan transacciones en tiempo real para identificar comportamientos sospechosos que podrían indicar fraude. Esto no solo mejora la seguridad, sino que también aumenta la confianza de los clientes en las instituciones financieras.
2. Retail: Personalización de la experiencia del cliente y optimización de precios
En el sector retail, el Machine Learning está revolucionando la manera en que las empresas entienden y atienden a sus clientes. Al analizar datos de comportamiento de compra, modelos de ML pueden predecir qué productos interesarán a cada cliente, permitiendo a las tiendas ofrecer recomendaciones personalizadas. Esta personalización mejora la experiencia del cliente, aumenta la satisfacción y, en última instancia, impulsa las ventas.
Además, el ML se utiliza para la optimización dinámica de precios, donde los precios de los productos se ajustan en tiempo real en función de la demanda, la competencia, y otros factores externos. Esto permite a las empresas maximizar sus márgenes de ganancia y responder rápidamente a las condiciones del mercado.
3. Manufactura: Mantenimiento predictivo y optimización de la cadena de suministro
En la manufactura, el Machine Learning se está utilizando para prever fallos en el equipo y optimizar la cadena de suministro. A través del análisis de datos históricos de máquinas, los modelos de ML pueden predecir cuándo es probable que un equipo falle, permitiendo a las empresas realizar mantenimiento preventivo antes de que ocurran problemas graves. Esto reduce el tiempo de inactividad y los costos asociados con las reparaciones de emergencia.
Asimismo, el ML optimiza la cadena de suministro al prever la demanda de productos, gestionar inventarios de manera más eficiente y reducir los tiempos de entrega. Esto no solo mejora la eficiencia operativa, sino que también incrementa la satisfacción del cliente al garantizar que los productos estén disponibles cuando se necesitan.
4. Recursos Humanos: Predicción de rotación de empleados y mejora del proceso de contratación
En el ámbito de los recursos humanos, el Machine Learning está siendo utilizado para predecir la rotación de empleados y optimizar el proceso de contratación. Al analizar datos de empleados actuales y anteriores, los modelos de ML pueden identificar patrones que sugieren cuándo un empleado podría estar considerando dejar la empresa, lo que permite a las organizaciones intervenir proactivamente para retener talento.
Además, el ML mejora el proceso de contratación al analizar currículums, cartas de presentación, y datos de entrevistas para identificar a los candidatos más adecuados para un puesto específico. Esto no solo acelera el proceso de selección, sino que también aumenta la probabilidad de que la persona contratada tenga éxito en su rol.
¿Por qué el Machine Learning es tan importante para las industrias actuales?
En un entorno empresarial cada vez más complejo y competitivo, la capacidad de una empresa para adaptarse rápidamente a los cambios en el mercado es crucial para su éxito. Aquí es donde el Machine Learning (ML) juega un papel fundamental. Al permitir que las máquinas aprendan de los datos y mejoren sus predicciones con el tiempo, el ML ofrece a las empresas una herramienta poderosa para tomar decisiones más informadas, optimizar procesos y crear nuevas oportunidades de negocio.
Impacto en la toma de decisiones
Uno de los beneficios más importantes del Machine Learning es su capacidad para transformar datos en decisiones accionables. A medida que las empresas recopilan cada vez más datos, desde el comportamiento del cliente hasta las operaciones internas, el desafío es convertir esta enorme cantidad de información en conocimientos útiles. El ML permite a las empresas analizar rápidamente grandes volúmenes de datos y extraer patrones y tendencias que no serían evidentes de otra manera.
Por ejemplo, en el sector financiero, un modelo de Machine Learning puede analizar el historial de transacciones de millones de clientes para identificar aquellos con un alto riesgo de incumplimiento, permitiendo a la institución financiera ajustar sus estrategias de préstamos. De manera similar, en el retail, el ML puede ayudar a prever la demanda de productos y ajustar las estrategias de inventario en consecuencia.
Eficiencia operativa y reducción de costos
El Machine Learning también es crucial para mejorar la eficiencia operativa. Al automatizar tareas repetitivas y optimizar procesos, el ML permite a las empresas reducir costos y aumentar la productividad. Por ejemplo, en la manufactura, los modelos de ML pueden predecir cuándo un equipo es probable que falle, lo que permite un mantenimiento preventivo oportuno y evita costosos tiempos de inactividad.
Además, en la gestión de la cadena de suministro, el ML puede optimizar el flujo de productos al predecir la demanda con mayor precisión, lo que reduce el exceso de inventario y los costos de almacenamiento. Al mejorar la eficiencia en estas áreas clave, las empresas pueden ofrecer productos y servicios a un costo más bajo, lo que aumenta su competitividad en el mercado.
Creación de valor y ventaja competitiva
La capacidad del Machine Learning para transformar datos en valor tangible es quizás su mayor contribución al entorno empresarial moderno. Al comprender mejor a sus clientes, optimizar operaciones y prever tendencias futuras, las empresas pueden desarrollar productos y servicios que satisfagan de manera más efectiva las necesidades del mercado.
Además, las empresas que implementan con éxito el ML tienen una ventaja competitiva significativa. Pueden reaccionar más rápidamente a los cambios en el mercado, personalizar experiencias para sus clientes de manera más efectiva, y operar de manera más eficiente que sus competidores que no utilizan estas tecnologías. Esta ventaja puede ser decisiva en mercados altamente competitivos donde la capacidad de adaptarse y evolucionar rápidamente es clave para el éxito a largo plazo.
Cómo empezar con Machine Learning en una empresa
Implementar Machine Learning en una empresa puede parecer una tarea desalentadora, especialmente si es la primera vez que se aborda este tipo de tecnología. Sin embargo, con los recursos adecuados y una estrategia bien definida, cualquier empresa puede comenzar a aprovechar los beneficios del ML para mejorar sus operaciones y tomar decisiones más informadas.
1. Definir los objetivos del negocio
El primer paso para implementar Machine Learning es tener una comprensión clara de los objetivos del negocio que se desean alcanzar. ¿Estás buscando mejorar la eficiencia operativa? ¿Deseas personalizar la experiencia del cliente? ¿O tal vez quieres predecir la demanda de productos para optimizar la cadena de suministro? Definir estos objetivos desde el principio ayudará a guiar todas las decisiones futuras y garantizará que el proyecto de ML esté alineado con las metas estratégicas de la empresa.
2. Recolectar y preparar los datos
Los datos son el combustible que impulsa el Machine Learning. Para que un modelo de ML sea efectivo, necesita alimentarse de datos de alta calidad que estén bien organizados y sean representativos del problema que se está intentando resolver. Esto implica recolectar datos de diferentes fuentes dentro de la empresa, como bases de datos de clientes, registros de ventas, y datos operativos, y luego limpiarlos y prepararlos para su análisis.
Una vez que se hayan recolectado los datos, es importante realizar un análisis exploratorio para entender su estructura, identificar patrones y detectar posibles problemas, como datos faltantes o valores atípicos. Este análisis inicial no solo ayuda a preparar los datos para el entrenamiento del modelo, sino que también proporciona valiosos insights que pueden influir en las decisiones empresariales.
3. Seleccionar las herramientas y tecnologías adecuadas
Existen muchas herramientas y plataformas disponibles que pueden facilitar la implementación de
Machine Learning en una empresa, desde bibliotecas de código abierto como
scikit-learn, TensorFlow y PyTorch, hasta plataformas en
la nube como AWS, Google Cloud y Azure. La elección de la herramienta adecuada dependerá del
caso de uso específico, la infraestructura existente y el nivel de experiencia técnica del
equipo.
Para empresas que están comenzando, puede ser útil empezar con plataformas en la nube que ofrecen servicios de ML gestionados, como AWS SageMaker o Google Cloud AI, ya que estas soluciones permiten a las empresas construir, entrenar y desplegar modelos de ML sin necesidad de gestionar la infraestructura subyacente.
4. Entrenar, evaluar y ajustar el modelo
Con los datos preparados y las herramientas seleccionadas, el siguiente paso es entrenar un modelo de Machine Learning. Esto implica seleccionar un algoritmo de ML adecuado para el problema en cuestión, entrenar el modelo con los datos disponibles y luego evaluar su rendimiento utilizando métricas clave como la precisión, la exactitud y la matriz de confusión que discutimos anteriormente.
Es importante recordar que el primer modelo entrenado raramente será perfecto. El proceso de entrenamiento de un modelo es iterativo, lo que significa que es probable que necesites ajustar los hiperparámetros, probar diferentes algoritmos, o incluso recolectar más datos para mejorar el rendimiento del modelo. La evaluación continua y el ajuste fino son cruciales para asegurar que el modelo final sea lo más preciso y robusto posible.
5. Desplegar el modelo y monitorear su rendimiento
Una vez que el modelo ha sido entrenado y evaluado, el siguiente paso es desplegarlo en un entorno de producción donde pueda empezar a generar valor para la empresa. Esto podría implicar integrar el modelo en un sistema existente, como un CRM o una plataforma de ventas, o crear una nueva aplicación que utilice las predicciones del modelo para tomar decisiones automatizadas.
Sin embargo, el trabajo no termina una vez que el modelo ha sido desplegado. Es crucial monitorear continuamente su rendimiento para asegurarse de que sigue siendo preciso y relevante a medida que cambian los datos y las condiciones del negocio. Si el rendimiento del modelo empieza a degradarse, puede ser necesario volver a entrenarlo con nuevos datos o ajustar sus parámetros para adaptarse a las nuevas circunstancias.
6. Capacitar al equipo y fomentar una cultura de datos
Finalmente, para que la implementación de Machine Learning sea verdaderamente exitosa, es esencial capacitar al equipo y fomentar una cultura de datos dentro de la organización. Esto implica no solo formar a los ingenieros y científicos de datos en las últimas técnicas de ML, sino también asegurarse de que todos en la empresa comprendan el valor de los datos y cómo pueden usarse para mejorar la toma de decisiones.
Al empoderar a todos los empleados con las habilidades y el conocimiento necesario para utilizar los datos de manera efectiva, las empresas pueden asegurarse de que el Machine Learning no sea solo una iniciativa técnica, sino una parte integral de su estrategia empresarial.
Conclusión
El Machine Learning ha emergido como una tecnología transformadora en el entorno empresarial moderno. Desde predecir el comportamiento del cliente hasta optimizar procesos de manufactura, el ML ofrece una amplia gama de aplicaciones que pueden mejorar la eficiencia operativa, reducir costos y proporcionar una ventaja competitiva significativa. A lo largo de este artículo, hemos explorado cómo el ML se diferencia de la inteligencia artificial en general, cómo funciona en un contexto empresarial, y por qué es tan importante para las industrias actuales.
También hemos examinado casos de uso específicos en sectores como finanzas, retail, manufactura y recursos humanos, demostrando cómo el ML está resolviendo problemas empresariales complejos y creando nuevas oportunidades de negocio. Implementar Machine Learning en una empresa requiere un enfoque estratégico, desde la definición de objetivos claros y la recolección de datos de calidad, hasta el entrenamiento y despliegue de modelos robustos.
La capacidad de convertir datos en decisiones accionables y predecir el futuro de manera precisa es lo que convierte al Machine Learning en una herramienta indispensable para las empresas que buscan mantenerse competitivas en un mundo cada vez más digital. Al empoderar a los empleados y fomentar una cultura de datos, las empresas pueden asegurarse de que el ML no solo sea una iniciativa técnica, sino un pilar central de su estrategia empresarial.
En resumen, el Machine Learning es mucho más que una tendencia tecnológica: es una pieza clave para la innovación y el éxito en la economía moderna. Ya sea que estés comenzando a explorar sus posibilidades o buscando optimizar tus modelos actuales, el camino hacia el aprovechamiento total del ML comienza con los primeros pasos que hemos descrito en este artículo.
Recursos adicionales
Para aquellos que deseen profundizar en el Machine Learning y su aplicación en el ámbito empresarial, aquí hay algunos recursos recomendados:
- Coursera - Machine Learning Specialization: Un curso especializado que cubre desde los fundamentos del ML hasta aplicaciones avanzadas.
- TensorFlow: Una plataforma de código abierto para la construcción y despliegue de modelos de ML, utilizada por empresas líderes en la industria.
- AWS SageMaker: Un servicio en la nube que permite a los desarrolladores y científicos de datos construir, entrenar y desplegar modelos de ML a gran escala.
- Scikit-learn: Una biblioteca de Python simple y eficiente para el análisis de datos y el aprendizaje automático.
- Machine Learning Yearning: Un libro de Andrew Ng que proporciona orientación práctica para implementar ML en la industria.
- Towards Data Science: Una comunidad online donde puedes encontrar artículos, tutoriales y guías sobre las últimas tendencias en ML y ciencia de datos.
Estos recursos proporcionan una base sólida para comprender y aplicar el Machine Learning en diversos contextos empresariales. Ya sea que estés comenzando tu viaje en ML o buscando mejorar tus habilidades, estas herramientas y plataformas te ayudarán a alcanzar tus objetivos.